

R. Scott Harris1 and Mike Cohn2
1 Montana State University–Billings
[email protected]
2 Mountain Goat Software, LLC
[email protected]
Abstract. Very little has been written to date on how to prioritize and sequence the development of new features and capabilities on an agile software development project. Agile product managers have been advised to prioritize based on “business value.” While this seems an appropriate goal, it is vague and provides little specific guidance. Our approach to optimizing “business value” uses tactics to minimize costs and maximize benefits through strategic learning. In order to provide specific and actionable advice to agile product managers, we present two guidelines. These guidelines are meant to provide a set of considerations and a process by which an agile product manager can achieve the goal of optimizing “business value” while recognizing that different product managers will vary in their notions of what “business value” is.
1 Introduction
Over the past seven years, agile software development processes such as Scrum [1], Extreme Programming [2], Feature-Driven Development [3], and DSDM [4] have emerged and their use has become much more prevalent. Central to these processes is a reliance upon emergent requirements and architecture. On an agile project, there is no upfront requirements engineering effort. Instead, the project begins with very high level requirements, often in the form of “user stories” [5]. The project team builds the software through a series of iterations and a detailed understanding of the requirements is sought only during the iteration in which software supporting those requirements is written.
A key tenet of agile processes is that these requirements are prioritized by a customer [2], customer team [6], or “product owner” [1] acting as a proxy for the end users of the intended system. Throughout this paper we will use the term product manager to represent this role independent of the specific agile process employed.
Product managers are given the relatively vague advice to prioritize based on business value [7][8]. Beyond this, very little specific advice has been offered to agile product managers about how to prioritize features. In this paper, we argue that product managers need to consider more than just the “business value” of each feature and we present additional guidelines for prioritizing requirements on agile projects. As an example of their usefulness, we then discuss the implications of these guidelines on agile software development projects.
2 The Problem Facing Product Managers
Sixty years ago, Nobel Laureate F. A. von Hayek wrote, “If we possess all the relevant information, if we can start out from a given system of preferences, and if we command complete knowledge of available means, the problem which remains is purely one of logic.” [9] “The problem” that Hayek refers to is the problem of organizing and coordinating people and resources to achieve a desired end. He argued that any one person does not and cannot possess all relevant information or knowledge sufficient to render decision-making a mere exercise in logic. More recently, Jensen and Meckling have applied Hayek’s work to business decision-making and organizational structures. [10], [11] Their work builds on Hayek’s differentiation between two types of knowledge: “scientific knowledge” and “knowledge of the particular circumstances of time and place.” [9]
“Scientific knowledge” is knowledge that is universal and can, for example, be taught in schools. In software development, knowledge of various programming languages and specific algorithms is “scientific knowledge.” A challenge on any software development project is obtaining the “knowledge of the particular circumstances of time and place” regarding what the customer and users want. This is confounded by the fact that often users do not know precisely what they want and means not only that the customer and users must learn what they want, but that the product manager must also learn what they want.
In software development, learning can be roughly divided into two categories: (a) learning what it is that users need and (b) learning the best way to develop software to meet those needs. Participatory design [12], essential use cases [13], and user stories [5] are techniques that have been developed to address the former; educated guessing and trial and error can be efficient ways to generate the latter. It may seem anomalous to claim that “trial and error” can be efficient, but in a world where it is impossible to define all requirements upfront and projects have some amount of emergent requirements, experimentation may be the cheapest way to learn if an idea, application, or program will either work or satisfy a user’s desires.
This is not to suggest that the process of learning should be the result of random trials and successes or errors. When making a decision about which features to work on next, there are a number of potential attributes of each feature that the agile product manager can and should consider. The purpose of this article is to suggest a few guidelines that will assist in making that decision.
Product managers on traditional, sequential projects have received guidance on how to prioritize requirements. Karlsson and Ryan, for example, recommend pair-wise comparisons among all candidate requirements [14] using Saaty’s analytic hierarchy process (AHP) [15]. Karlsson, Wohlin, and Regnell evaluated six different methods for prioritizing requirements [16]. Each approach involved pair-wise comparisons and, not surprisingly, they found AHP to be “the most promising approach.” Karlsson, Wohlin, and Regnell conclude that while AHP is promising it will have troubles scaling for use on industrial applications. Their experiment involved the prioritization of eleven requirements. Since n • (n−1) / 2 pair-wise comparisons are required to prioritize n requirements, their experiment required only 55 comparisons. While this approach has theoretical merit, enthusiasm is tempered when one realizes that what works for an experiment with eleven requirements may not work on even a relatively small industrial system where 4,950 pair-wise comparisons would be needed on a project with 100 requirements.
A significant problem with these traditional approaches to prioritization is that they are meant to be run once at the start of the project. Planning to re-run them once per iteration would be cost-prohibitive. Implicit in these approaches is the assumption that there is no expectation that one will need to account for new information or learning during the project. At the start of a project the requirements are ranked from 1 to n and the expectation is that the order will not change. Certainly for an agile project (and most likely even for a traditional project) this is an overly simplistic view. Through its use of end-of-iteration reviews an agile team will learn more about the relative desirability of each feature. This will (or should) alter the prioritization.
Whereas traditional teams have received guidance on prioritizing requirements, next to nothing has been provided for agile teams. The current practice in agile software development is to prioritize based on “business value.” While we might agree with the concept, there is little operational direction given to explain what “business value” means. Telling an agile team to prioritize based on “business value” gives as much guidance as having the president of General Motors order a lathe operator to “maximize corporate profits.” There is absolutely nothing in that dictum that conveys what the lathe operator needs to know—that is, what he should do next. Likewise, product managers have to make specific decisions about what to do next on an agile project. Our guidelines are meant to provide a set of considerations and a process by which a product manager can achieve the goal of maximizing “business value” while recognizing that different product managers will vary in their notions of what “business value” is.
Our focus is on how learning can affect product management. We assume that the “scientific knowledge” is properly vested in those who need it; what remains is optimal acquisition of “particular knowledge of time and place” as it pertains to a software project. This is knowledge that is acquired through the process of developing the software. Any non-iterative approach to doing this either ignores the crucial issue of learning or it assumes that ALL necessary knowledge is already vested in the decision maker. Therefore, we rejected the possibility of discovering or refining a static model to rank features in favor of suggesting guidelines for a dynamic process.
3 Guidelines for Prioritization
We define two issues of concern: “learning” and “the cost of change.” Though these two concepts are generally interdependent (i.e., the more one learns, the lower will be the cost of change), and related in a manner that depends on specific and particular features, we separate the issues to emphasize how to address each.
The following sections present guidelines we believe will assist the product manager in the pursuit of optimizing “business value.” The importance of these guidelines will likely vary from decision to decision even on the same project. We also note that advice from these guidelines may conflict. In that event, individual product managers will be called upon to weigh the options and make a choice based on their experience.
3.1. Defer Features with High Expected Costs of Change
There are two aspects to what we call the expected cost of change for a feature. The first is the risk that a change will be needed; the second is the cost of making the change. The Expected Cost of Change (ECC) for a feature is the arithmetic product of the probability that change will be needed and the cost of making the change.
At any time on a project, every feature to be developed has an associated ECC. Each feature can be ordered from low to high. Those features that are both highly certain to remain unchanged throughout the project and that have a low cost of change will be the ones with the lowest ECC; those features that are very likely to change and that will impose a high cost to change will be the ones with the highest ECC. All others will fall in between.
When considering only ECC, total development cost can be minimized by developing features in order from lowest ECC first to highest ECC last. This leads to our first guideline for prioritizing features:
Guideline 1: Defer those features with a high expected cost of change.
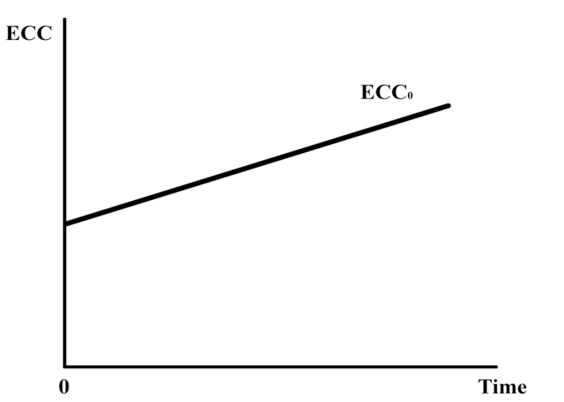
Fig. 1. The ECC curve.
Figure 1 shows a prioritization and sequencing of features from lowest to highest ECC. Several observations can be made about Figure 1:
1. The ECC0 curve shown orders development of all features from the lowest ECC to
the highest at the release of the project;
2. The total expected cost of change is the area under the ECC0 curve over the relevant time period;
3. The placement and slope of ECC0 curve assumes that the ECC over the course of the project is unaffected by learning. That is, there is no new knowledge gained in the process of developing the low ECC features that affects the ECC of higher ECC features.
This last observation seemingly negates the premise that it matters what order the features are produced since any combination of ordering yields the same total ECC. To see why it is important to shift earlier the features with the lowest remaining ECC, consider the effects of learning on the ECC: (a) as the product manager learns more about the product, the probability of future changes is reduced; and (b) as the whole team learns more about their capabilities, each other, the technologies in use, the domain, and other technical aspects of the project they will have more certainty about the best way to progress. Because of greater certainty on both of these fronts, the ECC for future features is reduced. Also, as the project progresses there will be lessened developer uncertainty about the technical dimensions of the project.
The result is there is a “family” of ECC curves for a project that reflects different levels of risk of change. Movement from one level of risk to lower levels occurs as new information is acquired about how best to proceed. This is shown in Figure 2.
As one becomes more and more certain regarding future feature set composition and definition as well as the technical aspects of the project the probability of future change falls. This causes the ECC curves to shift downward successively from ECC0 to ECC1, ECC2, and ECC3 over time. In figure 2, we have shown four representative ECC curves at the discrete times labeled 0 through 3. Learning and reassessment of future options is more likely to occur more frequently, approaching a continuous process. In that case, the family of ECC curves would be much larger.
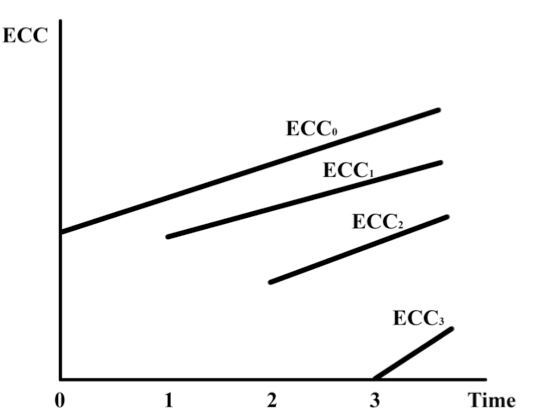
Fig. 2. Family of ECC curves for new levels of knowledge over time.
Note that each of the ECC lines is still upward sloping, though the slope and the ordering of the remaining risky features may change in each ECC curve since learning may affect the expected risk of change associated with some features more than with others. Therefore, it is not expected that the different ECCs would be parallel.
It is possible for the ECC at any point in time to have a next value of zero. In figure 2, the ECC3 curve shows this. This means that at time 3 the next feature has zero probability of change—though there still is uncertainty regarding remaining features as shown by an upward-sloping and positive remaining part of ECC3.
Finally, when the project is nearing release, the last feature will have a zero ECC because as all available learning has already occurred and, by definition, if you are done, there are no further expected changes
With learning and constant continuous recalculation of the ECCs as a project progresses, the overall “Composite ECC” can be minimized. This is shown in Figure 3.
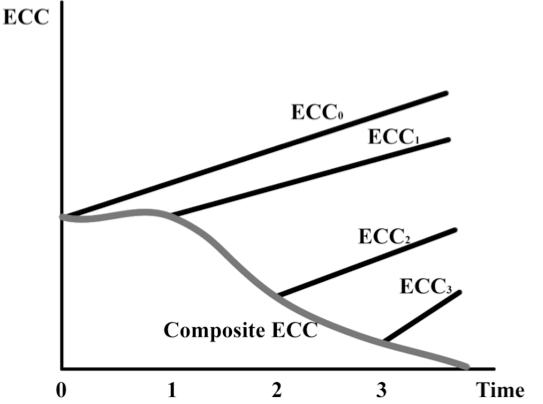
Fig. 3. Composite ECC curve with learning.
If there is a continuum of learning (where the ECC curves shown in figure 3 are discrete examples at times 0, 1, 2, and 3) then the “Composite ECC” with learning is the heavy gray line derived from the locus of points that trace out the points on the ECC curves as they shift with learning over time.
If one wants to plan to minimize the total expected cost of change when learning takes place by minimizing the area under the Composite ECC line, it is now evident that sequential decisions have to be based on (1) prioritizing activities that will have the greatest impact to lower future ECC curves and (2) deciding which remaining individual feature has the lowest ECC. In doing so, we should note that it is possible that these two criteria may not yield the same immediate priority activity. In that case, the product manager or team will have to weigh the merits of the two different possible actions. We now explore the implications of prioritizing activities based on their expected impact on future expected cost of change.
3.2. Bring Forward Features That Generate Useful Knowledge
Just as different features will have different ECCs, each feature may have a different impact on learning. For example, developing one feature may greatly inform the product manager about the desirability of a feature set or the usability of the main user interface workflows. Developing a different feature may have a much smaller impact on the amount of new knowledge gained by the product manager. Similarly, developing different features will impart different amounts of knowledge to the developers creating the product. This leads to our second guideline for prioritizing features:
Guideline 2: Bring forward those features that will generate more (or more useful) knowledge.
To separate the effects of the ECC and learning on decision-making, suppose that the expected cost of change for all features were the same; the ECC curves would all have a slope of 0. In that event, project features should be prioritized solely according to the degree of expected learning each feature would add to the knowledge necessary to successfully complete the project. Doing so would shift the subsequent ECC curves downward fastest. This effectively defines an operational definition of learn- ing as the acquisition of knowledge that shifts future ECC curves downward. Throughout the project, those remaining features that are expected to generate the most learning should be done first.
These two guidelines can be used together to address the likely situation of differential impacts a particular feature will have on learning and expected cost of change. In figure 4, the vertical axis measures ECC and the horizontal measures expected learning. The axes are set so it is preferred to be further away from the origin. (Since a lower ECC is better than a higher one, the vertical axis shows decreasing ECC the further one is from the origin).

Fig. 4. Expected knowledge generated
Points A, B, C, and D represent four different features placed on the graph according to both their ECCs and the expected knowledge each will generate. As we shall see, at any point in time, it is sufficient to identify only the feature that will be developed next. In this example, feature D is expected to generate more knowledge about how to proceed with the project and has a lower expected cost of change and would, therefore, be the choice to undertake next. On the other hand, if D did not exist, and the only choices were A, B, and C, the answer of which to do is less clear. Either B or C is better to undertake than A, but the choice between B and C depends on the trade-off that one is willing to make between ECC and the expected knowledge gained.
The reader is cautioned that figure 4 represents a snapshot at a particular time when all features—A, B, C and D—are candidates for doing in the immediate next iteration. The choice of doing feature D next would generate a new scatter diagram showing only the remaining features. If the completion of D generated new knowledge, it is almost certain that the remaining features will then shift from the positions shown in figure 4. Indeed, the subsequent diagram may show very little residual resemblance to a prior one. In our example, the following are all possible outcomes of the learning that accrues by doing D: (a) the relative ranking of the remaining features changes (e.g., feature A becomes a higher valued choice than either B or C); (b) an uncompleted feature is discovered to be unnecessary (e.g., feature C is found to be not needed); and/or (c) a new, previously unidentified feature is found to be necessary for the successful completion of the project (e.g., feature E is added to the mix). The placement of those remaining features in the new diagram could change the relative ranking.
3.3. Incorporate new learning often, but only to decide what to do next.
We emphasize that learning is both important and a continuous and cumulative process that can change the priority of what is best to do next. This implies that a product manager and agile team must be nimble and constantly prepared to alter plans based on newly acquired knowledge. Indeed, it should be clear that becoming wedded to a plan that is any longer than the next activity is both costly to formulate (if any time is spent on it) and could lead one in the wrong direction (e.g., planning to do either B or C after completing D—as would be implied from Figure 4—rather than choosing A if it became the best remaining option given the knowledge acquired from doing D). While it was useful in illustrating the points made in the previous section, an underlying assumption necessary to draw figure 4 was that each of the four features was ranked against the other three. In fact, full pair-wise ranking of features beyond what will be done in the immediate next iteration is unnecessary.
Because learning is a continuous process, decisions are both simplified and bounded. The sequence of decision-making only requires that one decide on the immediate project, user story, or feature to develop next. We realize that at each step there is a tendency to want to immediately plan the full order in which all expected features will be programmed—including those that will not be attempted in the upcoming iteration. However, all that is necessary is to decide what will be done next each step of the way and not concern oneself with the order of deferred activities. Sort the features into just two categories: what to do “now” versus “not now.” Those features that are not done “now” will then be reevaluated for the next iteration when there is more knowledge upon which to base the evaluation. This is sequential planning where the “plan” is in the process and not the result. Without it, there is no agil- ity in agile processes. This leads to our third guideline:
Guideline 3: Incorporate new learning by prioritizing only as many features as can be completed in the coming iteration.
It should be noted that this guideline is consistent with and supports the agile preference for short iterations. While it is often useful to have a loosely-defined release plan covering the likely set of features to be delivered over the course of a small number of months, the detailed work of prioritizing and sequencing features should only be done an iteration at a time.
4 Implications
In this final section we consider an example of how these guidelines can be applied to the practical decisions of a project. These guidelines are presented to clients in both training classes and in consulting discussions. We have found it best to tell clients to perform a rough, initial prioritization of the desired features based on the nebulous “business value” provided by each. We stress that it is not necessary to prioritize all remaining features and normally guide product managers to plan two or three times as much as they expect the team to be able to complete in a single iteration. For these items product managers are given the guidance to think of expected cost of change and knowledge generated as “sliders” that can move a feature ahead or backward within the prioritization. Product managers then review the selected features sliding them forward and back based on considerations of expected cost of change and expected knowledge generated.
Following this process, we find that features with architectural implications that will not have exceptionally high expected costs of change but that will increase knowledge dramatically can justifiably be developed in an earlier iteration than would be justified by prioritization solely on business value. We have applied the guidelines in this way to support the early selection of a particular application server. We have also used this on projects to justify the higher prioritization of features that influenced design approaches for a security framework as well as internationalization and localization. Similarly, when applied in this way, the guidelines can support the earlier development of features that generate significant learning about the main metaphors of the user experience being designed.
On the other hand, features with a high expected cost of change that will provide little new knowledge, should be deferred. By deferring such features we put their design off to the point where our knowledge about the product and system has increased and to where we can presumably make better decisions about those features with an initially high expected cost of change. Further, since developing these features would not provide significant new knowledge to the product manager or team, we are able to defer these features while foregoing no opportunities to learn. We have applied the guidelines in this way to a project struggling to choose between three competing client technologies. This decision was deferred while maximizing the team’s learning through the development of other features.
Through the application of these guidelines on commercial projects we are able to provide more guidance to agile product managers than the conventional “prioritize based on business value.” We have found that instructing them to consider relative changes in the cost of change and, more importantly, the amount of knowledge gener- ated by the development of a feature leads to better decisions. Most importantly, the guideline-based approach described here requires very little effort and allows the product manager to make easier decisions such as “what one thing should be done next” rather than the harder “what is the full set of priorities.” This more iterative approach to prioritization acknowledges that learning occurs throughout a development project and is more consistent with the agile management of software develop- ment projects.
References
1. Schwaber, K., Beedle, M.: Agile Software Development with Scrum. Prentice-Hall, Upper Saddle River, NJ (2001).
2. Beck, K.: Extreme Programming Explained: Embrace change. Addison-Wesley, Upper Saddle River, NJ (1999).
3. Palmer, S.R., Felsing, J.M.: A Practical Guide to Feature-Driven Development. Addison-Wesley, Upper Saddle River, NJ (2002).
4. Stapleton, J.: DSDM: Business-Focused Development, 2nd edn. Pearson Education, Upper Saddle River, NJ (2003).
5. Cohn, M.: User Stories Applied for Agile Software Development. Addison-Wesley, Upper Saddle River, NJ (2004).
6. Poppendieck, T.: The Agile Customer’s Toolkit at www.poppendieck.com.
7. Andrea, J.: An Agile Request For Proposal (RFP) Process. Proceedings of the Agile Devel-
opment Conference, Salt Lake City, UT (2003) 152–161.
8. Augustine, S.: Great COTS! Implementing Packaged Software With Agility. Presentation at
Agile Development Conference, Sydney, Australia (2004).
9. Hayak, F.A.: The Use of Knowledge in Society. American Economic Review, Vol. XXXV,
No. 4 (Sept. 1945) 519–530.
10.Jensen, M.C., Meckling, W.H., Baker, G.P., Wruck, K.H.: Coordination, Control, and the
Management of Organizations: Course Notes. Harvard Business School Working Paper
#98-098 (October 17, 1999).
11. Jensen, M.C., Meckling, W.H.: Specific and General Knowledge, and Organizational Struc-
ture. In Werin, L., Wijkander, H. (eds.): Contract Economics. Blackwell, Oxford (1992). Also published in Journal of Applied Corporate Finance (Fall 1995) and Jensen, M.C.: Foundations of Organizational Strategy. Harvard University Press, Boston (1998).
12. Schuler, D., Namioka, A. (eds.): Participatory Design: Principles and practice. Erlbaum, Hillsdale, NJ (1993).
13. Constantine, L.L., Lockwood, L.A.D.: Software for Use. Addison-Wesley, Reading, MA (1999).
14. Karlsson, J., Ryan, K.: A Cost-Value Approach for Prioritizing Requirements. IEEE Soft- ware, Vol. 14, no. 5 (1997) 67–74.
15. Saaty, T.L.: The Analytic Hierarchy Process. McGraw-Hill, New York (1980).
16. Karlsson, J., Wohlin, C., Regnell, B.: An Evaluation of Methods for Prioritizing Software Requirements. Journal of Information and Software Technology, Vol. 39, No. 14–15 (1998)
939-947.
Last update: January 7th, 2022





